Introduction
Nous allons aujourd’hui nous intéresser à une certaine (ubber) approche de développement qui pourrait convenir à beaucoup. Celle de déployer des WCF auto-générés sur Azure à partir d’un modèle Code First Entity Framework.
Mais quelle langue il nous parle là ? Oui en effet quelques rappels s’imposent.
Entity Framework : Technologie .NET poussée depuis quelques années pour l’accès et la manipulation des données qui permet de faire abstraction du moteur de bases qui tourne en dessous. Couche d’accès aux données. Ce que ça change dans l’approche de développement c’est que vous manipulez uniquement des objets (entités) et non plus des enregistrements en base (donc plus de requête SQL à écrire, meilleures possibilités de débug etc)
Code First : Avec l’entity framework il y a trois approches de développement possibles. Model First à partir d’un schéma (edmx) vous concevez votre couche d’accès aux données et modèle sous-jacent. Database First vous partez d’une base de données existante pour générer la couche d’accès aux données. Code First, disponible depuis la version 4.1, vous définissez vos classes (qui représenteront votre couche d’accès aux données, vous les tagguez et ça vous génère votre modèle de base de données.
WCF : Windows Communication Foundation, sous ensemble du .NET Framework de technologies de communication inter-applications et unification des modèles de développement sur ces mêmes technologies (abstraction, factorisation du code, rapidité de développement…). Ici c’est la partie Web Services qui nous intéresse et plus particulièrement WCF Data Services.
Azure : Service de cloud computing proposé par Microsoft au niveau IaaS et PaaS. Vous permet d’héberger bases de données, services web, machines virtuelles…
Maintenant qu’on a dégrossi les briques principales de notre méthodologie nous allons rentrer un peu plus dans le détail.
L’objectif de cet article n’est pas d’expliquer comment on fait un modèle de base de données en Code First ni comment on crée un web service mais plutôt de vous proposer une méthodologie.
Pour le reste c’est assez bien expliqué ici https://blogs.msdn.com/b/adonet/archive/2011/03/21/using-wcf-data-services-with-entity-framework-4-1-and-code-first.aspx
Pré-requis
Pré-requis logiciels :
Visual Studio 2010 à jour
Le SDK Azure à jour
Entity Framework 4.1 ou supérieur (disponible ici https://www.microsoft.com/download/en/details.aspx?displaylang=en&id=8363 ou via Nugets)
WCF Data Services https://www.microsoft.com/downloads/fr-fr/details.aspx?familyid=5b1a903e-59e2-46e8-b63b-a9421bbb6bf9
Un compte sur Azure
Pré-requis utilisateur (savoir-faire) :
Notions sur le .NET Framework
Notions sur Visual Studio
Notions d’architectures N-Tiers
Architecture et détails
La méthodologie consiste à créer notre couche d’accès aux données avec Entity Framework Code First (parce que ça va très vite et que c’est très bien) puis d’exposer ce contexte de base de données au travers de services OData (WCF Data Services) et enfin de déployer le tout sur Windows Azure (ce qui n’est pas forcément le plus simple). Le contexte de base de données ira quant à lui utiliser une base de données SQL Azure.
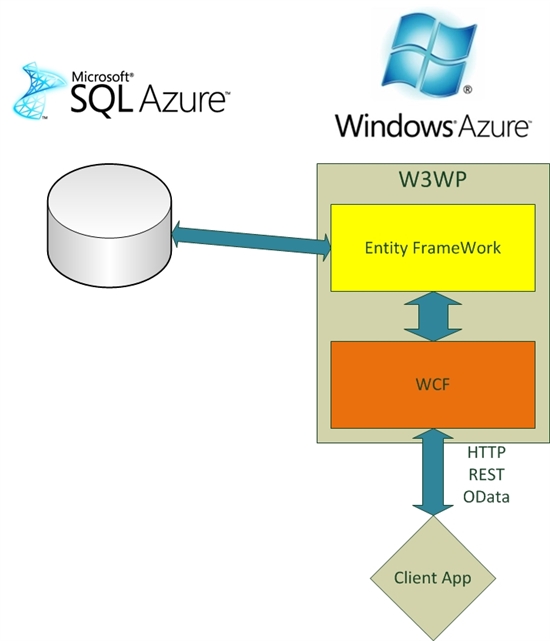
OData est un standard de publication des données et d’interaction avec celles-ci, le principe étant de respecter le protocole HTTP au maximum :
Chaque élément à une url unique
Chaque opération respecte les Verbes HTTP
Nous aurons ainsi un web service CRUD sans avoir à développer chacune des opérations :
Create via le verbe HTTP POST.
Read via le verbe HTTP GET
Update via les verbes HTTP PUT ou MERGE (selon le cas de figure)
Delete via le verbe HTTP DELETE
L’avantage en respectant ces standards c’est que ce sont justement des standards, aujourd’hui vous développez un cœur applicatif en .NET (sage décision) mais demain votre ami développeur Java, JavaScript/HTML5, Silverlight ou Objective-C qui voudra interagir avec vos données pourra aussi le faire. (Et ils vécurent heureux et eurent beaucoup d’applications ensemble dans un monde fait de standards et d’interopérabilité)
Enfin, pourquoi déployer sur Windows Azure & SQL Azure ? Pour les avantages qu’on y connait, rapidité de déploiement (pas besoin d’acheter son serveur, de configurer et d’installer une dizaine de produits Microsoft etc.), rationalisation des coûts (on ne paie que ce qu’on utilise), robustesse, montée en charge.
Bref vous l’aurez bien compris, l’objectif de cette méthodologie est de développer rapidement (mais pas n’importe comment) des applications à faible coût, fiables et à forte évolutivité.
Adapter un livrable WCF Data Services + EF Code first pour Azure
On va partir du principe que vous avez lu et mis en pratique les quelques articles cités plus haut et que vous disposez d’une couche d’accès aux données qui fonctionne avec un WCF Data Service qui expose tout correctement en local (autant pour la base de données que pour le web service).
Vous avez donc deux projets au sein de votre solution :
Un projet de type librairie qui contient votre DAL (Data Access Layer)
Un projet de type Web Application qui contient votre service OData
A partir de là il nous reste plusieurs choses à faire :
Créer une instance de base de données sur SQL Azure et une base de données. (je préfère vous demander de chercher, en effet l’interface est assez souvent mise à jour et d’ici à ce que vous lisiez cet article ça aura surement changé)
Déployer le modèle de base de données.
Créer un « hébergement » pour votre web service sur Windows Azure (idem)
Créer un projet Azure au sein de votre solution
Modifier quelques éléments de votre solution
La base de données
Commençons donc par la base de données, normalement pour vos premiers tests en local elle a été déployée sur un serveur SQL et vous disposez de SQL Management Studio (si vous ne l’avez pas encore téléchargez le, c’est gratuit et très pratique quand on a besoin d’aller au-delà du déploiement automatisé de Visual Studio)
Commencez par vous connecter à l’instance SQL Serveur sur laquelle a été créée votre base de données (normalement SQLEXPRESS est installé avec Visual Studio, dans ce cas entrez en adresse .\SQLEXPRESS en authentification windows, si vous l’avez déployée ailleurs vous savez normalement comment vous y connecter).
Une fois cela effectué faites un clic droit sur votre base de données, tâches, générer les scripts. Tous les objets, vers une nouvelle fenêtre. Vous arrivez normalement sur un nouvel onglet avec des requêtes SQL. Ces requêtes sont des ordres DDL (Data Definition Language, c’est-à-dire des instructions servant à définir les structures de données au sein de la base) qui vont nous servir à déployer le modèle de base sur SQL Azure.
SQL Azure n’est pas un vrai serveur SQL à proprement parler, il est conçu de manière à supporter des centaines de milliers de bases de données ayant des besoins différents en termes de performances, volume de données etc. C’est pour cette raison qu’un certain nombre d’ordres SQL sont interdits sur SQL Azure (et aussi pour des problématiques de sécurité dans certains cas). Le script de création que nous venons de générer est lui à la base fait pour une exécution sur un vrai serveur SQL.
Il va donc falloir « nettoyer » le script avant de l’exécuter sur SQL Azure.
La première étape de ce nettoyage consiste à supprimer toutes les instructions précédant le premier CREATE TABLE. Vous pouvez ensuite effectuer plusieurs CTRL+H successifs pour rechercher et remplacer par rien (supprimer donc) les termes suivants :
PAD_INDEX = OFF,
, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
ON [PRIMARY]
SORT_IN_TEMPDB = OFF,
(Les virgules ont leur importance)
Une fois cela effectué il suffit d’exécuter le script sur la base de données, deux solutions s’offrent à vous :
Ou vous le faites depuis une nouvelle connexion et une nouvelle fenêtre de requête dans SQL Management Studio (pensez bien à ajouter votre IP publique dans les règles de pare-feu de votre instance SQL Azure)
Ou alors vous le faites depuis le portail de gestion SQL Azure
Note : je vous conseille de sauvegarder le script de création de la base dans Azure quelque part, ça peut servir.
Nous avons maintenant notre modèle de base de données déployé au sein d’une base de données elle-même hébergée par une instance SQL Azure. Nous allons maintenant nous pencher sur notre contexte de base de données.
Le contexte de base de données
Seconde étape : adapter notre contexte de base de données pour Azure. Souvenez-vous le contexte de base de données nous permet un accès aux données stockées dans notre base de données et collabore étroitement avec.
Pour ceux qui connaissent Entity Framework Database First et Model First il y a une nouvelle subtilité avec l’approche Code First, celle de DatabaseInitializer (en fait ça existait déjà mais c’était caché pour faciliter la vie au développeur)
L’idée de cet Initializer étant qu’à chaque instanciation de contexte il va vérifier la structure de la base de données pour vérifier si elle est conforme avec le code compilé et éventuellement effectuer des actions par la suite.
Celui qui est le plus souvent exposé est le DropCreateDatabaseIfModelChanges, c’est-à-dire que s’il détecte une différence entre le modèle compilé et le modèle en base, il supprime toute la structure de la base et la recrée. Ce n’est vraiment pas pratique pour deux raisons, la première c’est qu’au passage vous perdez vos données, la seconde c’est que les ordres de création utilisés sont conçus pour SQL Server et certains sont interdits.
Il nous reste donc plusieurs possibilités :
CreateDatabaseIfNotExists : comme son nom l’indique crée la structure de base si elle n’est pas présente, ne fait rien s’il détecte une différence. (mais idem pour la création ordres SQL Server interdits, d’où le fait que nous ayons effectué un déploiement au préalable à la main)
MigrateDatabaseToLatestVersion qui vous permet de gérer un cas de migration/mise à jour
… (liste des initializers fournis par défaut avec l’EF ici https://msdn.microsoft.com/en-us/library/system.data.entity(v=VS.103).aspx )
Initializer codé à la main
Ce qu’il faut bien comprendre c’est qu’il y a un ensemble d’instructions interdites dans SQL Azure et qu’il faut faire attention à ce que notre modèle de base de données ne les utilise pas. De plus il faut faire attention aux données et à ne pas faire sauter le modèle à la première occasion.
Personnellement j’ai donc choisi le CreateDatabaseIfNotExists et lorsque j’aurai des mises à jour de schéma de base de données à effectuer il me suffira de comparer une copie du schéma actuellement en production avec la nouvelle version grâce aux outils de visual studio (voir mon article à ce sujet visual-studio-2010-amp-les-out ) et de créer un script de migration SQL.
Maintenant que nous avons choisi un Initializer de contexte de base de données nous allons passer à la partie Web Service et web config.
Note : Pensez à la méthode Seed si vous avez besoin d’avoir un jeu d’enregistrements au démarrage au sein de votre base.
Le Web Service
Vous avez normalement un web service WCF Data Service qui fonctionne en local au sein d’une web application. Ce qui est vraiment sympa avec cette méthodologie c’est que vous n’avez qu’une dizaine de ligne de code à taper pour créer tout un CRUD au format web service pour votre base de données. Le tout en respectant des standards du web.
La première adaptation à effectuer est de mettre à jour la connectionString pour que le web service aille chercher ses données sur SQL Azure, c’est une opération assez simple et vous avez accès aux paramètres de connexion depuis les propriétés de votre base sur le portail de gestion Azure. Je vous laisse donc faire.
La seconde modification assez mineure est à effectuer au sein de web.config toujours, elle consiste à autoriser les verbes HTTP dont on a besoin. En effet, par défaut la sécurité est moins restrictive sur un serveur IIS classique que sur Azure (et il comporte plus de modules). Tous les verbes sont donc autorisés par défaut (d’autant plus que quand vous faites vos tests en local, bien souvent on ne s’en rend pas compte mais de l’authentification passe de manière quasi transparente, ce qui n’est le cas sur Azure). L’astuce consiste donc à paramétrer la web application pour qu’elle accepte tous les verbes sans authentification (ou de paramétrer de l’authentification au choix, mais on change de sujet)
Pour cela ajoutez cette balise <authentication mode="None"/> au sein de la balise system.web (qui est elle-même au sein de la balise configuration pour rappel)
Enfin, assurez-vous que toutes les références à EntityFramework, Microsoft.Data (toutes), et à votre projet de librairie qui contient la définition de votre modèle sont bien en copie locale au sein de votre projet de web application. (les vm Azure ne possèdent pas ces dll qui sont récentes)
Il est temps maintenant de déployer le web service.
Déploiement sur Windows Azure
Partons du principe que vous avez déjà un web role Azure de créé depuis votre interface de gestion Azure. (si vous ne savez pas comment faire, regardez sur internet, ça évolue assez souvent)
Depuis Visual Studio ajoutez un nouveau projet de type Azure au sein de votre solution, vous allez avoir un assistant, suivez les étapes sans ajouter aucun composant pour le moment.
Une fois l’assistant terminé effectuez un clic droit sur « roles » au sein du projet nouvellement créé et ajouter un « web role »à partir de la solution, sélectionnez le projet web qui contient votre web service.
Enfin faites un clic droit sur votre projet Azure et cliquez sur « Déployer », lors de la première fois un assistant s’ouvre pour configurer les paramètres de déploiement sur votre web role et ensuite le déploiement s’effectue (c’est long, c’est normal).
Une fois que votre déploiement est terminé ça y est vous avez un Web Service Data Service qui se base sur un contexte Entity FrameWork Code First qui va chercher ses données dans SQL Azure et qui est déployé sur Windows Azure !
Maintenant que vous avez vu que c’est extrêmement rapide de créer son modèle de base de données, sa couche d’accès aux données et la publication via web service vous pouvez passer plus de temps sur le développement réellement important (du moins pour l’utilisateur final) : le côté client.
Conclusion et remerciements
Cette méthodologie est vraiment rapide et carrée j’ai simplement quelques poitnts à relever :
Entity Framework 4.3 (dernière version au moment où j’écris l’article) ne supporte pas les énumérations pour le moment, ça arrive avec le 5 et je suis impatient.
Quand on utilise les WCF Data Services côté client, pour coller au standard on est obligé de gérer le tracking et le loading à la main, (loadproperty, addlink, setlink, deletelink…) ça vaudrait vraiment le coup d’avoir une évolution qui rende ça transparent.
L’asynchronisme côté client est pas encore très simple (surtout quand on voit ce qui arrive avec Windows 8) ce serait pas mal d’avoir des améliorations de ce côté-là aussi.
Merci à Pierre-Alexandre GURY SUPINFO B3 qui m’a beaucoup aidé en débug sur le sujet, en effet on travaille sur des versions de framework/librairies vraiment récentes et pas encore très bien documentées. J’espère qu’il aura bientôt un blog car il est vraiment très prometteur et sait déjà plein de choses.
Merci à Benjamin ARKI, qui a encore une fois pris de son temps pour relire et corriger un article de ce blog.