Introduction
Visual Studio comporte plusieurs outils souvent méconnus des développeurs pour ce qui est de la « gestion » des bases de données SQL Server. Ne vous êtes-vous jamais posé la question, après avoir modifié le fichier EDMX d’une application en production pour constituer une nouvelle version : « Comment être sûr de n’avoir rien oublié avant de mettre en PROD ?»
Ou bien encore après avoir joué des modifications sur les données en elle-même en production et en développement « comment vais-je faire pour avoir les mêmes données partout ? »
Visual Studio est capable de répondre à ces questions grâce à deux outils, celui de comparaison de schémas et celui de comparaison de données. Autour de notre exemple nous verrons aussi d’autres outils de « gestion » des données dans Visual Studio.
Rappels
Au fur et à mesure de la rédaction de l’article je me suis rendu compte que je ne pouvais pas aborder certains concepts sans avoir fait des rappels au préalable.
Microsoft SQL Server est un serveur de bases de données relationnelles (et tant qu’on est dans les rappels, il existe d’autres paradigmes de stockage des données, arborescent, raw, etc.), avec le temps il s’est étoffé de nombreux outils et fonctionnalités (Agent, Reporting Services, Analysis Services…).
Visual Studio 2010 est un environnement de développement intégré, de même avec le temps il a intégré de nombreux outils qui sont ou ne sont pas disponibles selon l’édition de Visual Studio que vous possédez. J’ai la chance de disposer de Visual Studio Ultimate, il se peut que certaines options n’apparaissent pas ou soient présentées différemment selon votre édition de Visual Studio.
Pour bien utiliser Visual Studio il faut bien saisir l’optique sous-jacente. Nous pouvons déjà distinguer plusieurs types « d’outils » dans Visual Studio :
Les outils de développement et de modélisation, c’est-à-dire que je conçois une application, je la développe et je la déploierai plus tard.
Les outils de gestion et de réingénierie, c’est-à-dire que mon application existe déjà (souvent dans une version différente) et on me demande d’intervenir sur quelque chose d’existant, de reprendre un travail etc.
A cela s’ajoute le sucre de l’IDE, c’est-à-dire l’intégration de ces outils les uns avec les autres qui vous permettent une industrialisation du développement et de la reprise de données plus facile.
A noter que Visual Studio n’est en aucun cas un outil d’administration, il y a des outils dédiés à cela. (SQL Management Studio dans notre cas)
Création du modèle de base
Pour illustrer mes exemples tout au long de cet article je vais commencer par créer un modèle EDMX. Si vous ne maitrisez pas cette partie du .NET Framework ce n’est pas grave vous pourrez comprendre la suite de l’article. J’aurais tout aussi bien pu créer une base de données SQL directement ou un projet de base de données). L’idée de cette sous partie n’est pas de vous apprendre à vous servir d’un EDMX, mais simplement de vous indiquer que j’ai aussi utilisé ces outils dans cet article et que ça existe. Voici tout de même quelques précisions sur la chose pour vous aider à comprendre, et je vous encourage à creuser ce sujet :
Cet outil (l’éditeur d’EDMX) fait partie de la classe « outils de modélisation et/ou de développement » citée plus haut.
Un EDMX est une modélisation objet-base de données qui permet de générer automatiquement la couche d’accès aux données au sein de projets ainsi que les scripts de création du contenu de la base. Pour en ajouter un à votre projet il suffit d’aller dans la section « données » du langage utilisé et de sélectionner ADO.NET Entity Data Model.
L’Entity Framework (technologie sous-jacente), les EDMX ainsi que les outils associés sont un vaste sujet (plusieurs livres y sont dédiés)
Autre précision sur l’Entity Framework, il y a trois approches pour ce qui est de la relation entre modélisation, accès aux données et génération de la base de données :
Code First : j’écris du code .NET directement qui définira mon modèle et générera directement les scripts de création de ma base.
Design First : j’utilise l’outil de design de mon modèle (avec ma souris) ce qui générera l’accès aux données et les scripts de création de la base de données.
Database First : j’ai déjà une base de données existante ou bien un projet de base de données (nous en reparlerons plus tard) dans ma solution et j’extrais ma couche d’accès aux données ainsi que ma modélisation de ce qui a déjà été définit au préalable.
Voici donc mon modèle de données (que vous pouvez quasiment lire comme un modèle de Merise en inversant les cardinalités pour ceux qui ne sont pas familiers avec les EDMX)
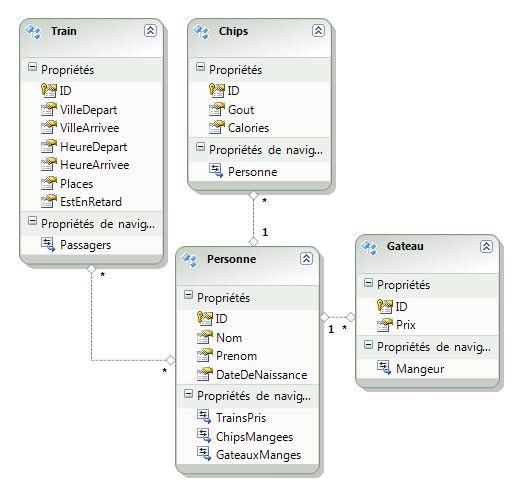
Vous noterez que ce modèle comporte des entités qui ont-elles mêmes des propriétés et sont liées entre elles ou non.
Imaginons que mon application soit partie en production, que des clients aient commencé à l’utiliser et que le client me demande d’effectuer des modifications qui vont impacter la structure de la base de données.
Outils de comparaison de schéma de la base
Par exemple je suis amené à effectuer les modifications suivantes :
Train.HeureDepart : String -> DateTime
Train.HeureArrivee : String ->DateTime
Train.Places : Int32 -> Double
Personne.DateDeNaissance : String -> DateTime
Ajout d’une table Soda
De telle manière que mon modèle évolue dans ce sens :
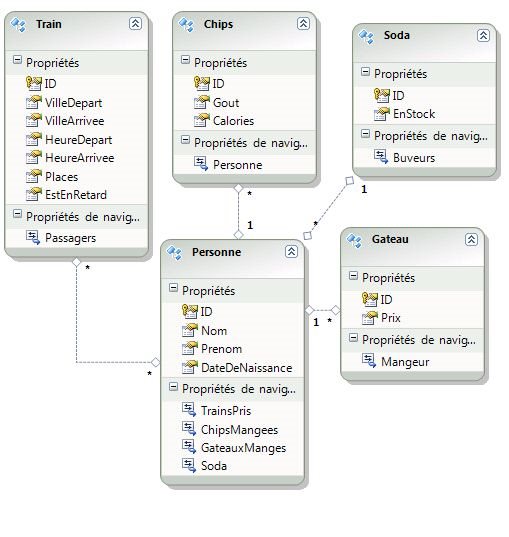
J’ai ainsi deux versions de ma base de données, une en production et une en développement que j’aimerais réconcilier afin de pouvoir passer la nouvelle version de mon application en production.
Pour cela cliquez dans Visual Studio sur « données », « comparaison de schémas », « nouvelle comparaison de schémas »
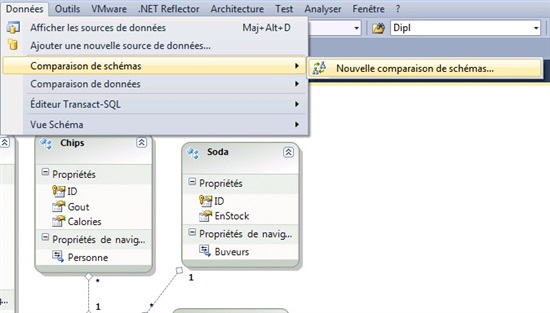
Une fenêtre s’ouvre alors
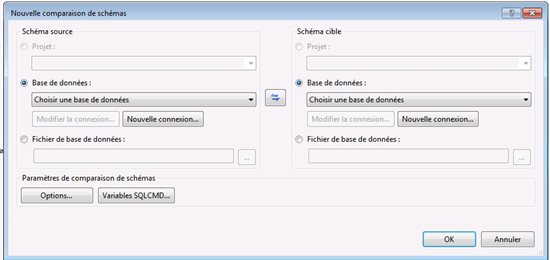
Il vous est demandé de sélectionner les deux schémas/base de données à comparer, la « source » étant la version la plus récente normalement afin de pouvoir verser les modifications dans la base de données de destination. Notez que vous pouvez effectuer cela d’un projet à un autre (comparaison d’edmx), d’une base de données en ligne à une autre ou d’un fichier de base de données à un autre (ainsi que toutes les combinaisons de ces choix)
Je me connecte donc à gauche à ma base de données de dev et à droite à celle de prod. (PENSEZ BIEN A FAIRE UN BACKUP AVANT DE LA BASE DE PROD) et je clique sur « ok ».
A ce moment Visual Studio lance la comparaison qui peut prendre quelques secondes à plusieurs dizaines de minutes selon la puissance de votre machine, la complexité des bases et la vitesse de connexion à ces dernières.
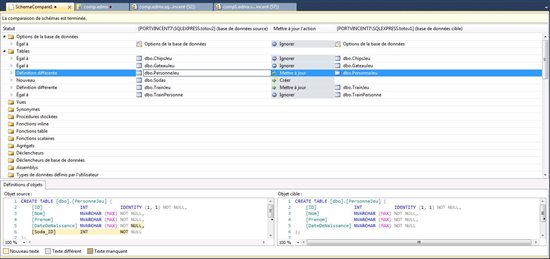
Une fois la comparaison effectuée vous visualisez un rapport tel que celui-ci qui met en évidence les différences et indique l’action à effectuer, en base vous pouvez voir la différence entre les requêtes de définitions.
Notes : Pensez bien à lire l’intégralité du rapport avant de jouer les modifications, en bas figurent aussi des comparaisons telles que les options de sécurité de la base, les fichiers de logs etc.
Un élément qui comporte directement l’action « ignorer » juste après la génération du rapport est un élément identique sur les deux versions de la base (vous avez un statut plus précis dans la colonne de gauche)
Paramétrez vos mises à jour et cliquez sur «écrire les mises à jour » dans la barre d’outils, notez que si la mise à jour est plus complexe (ex, reprise de données) vous disposez d’un bouton « envoyer les mises à jour à l’éditeur » qui vous permettra de modifier le script de mise à jour avant de le jouer.
Une fois cela effectué, vous pouvez contrôler que tout est correctement effectué en actualisant la comparaison.
Note : sur des modifications plus lourdes (cardinalités entre les tables notamment) il sera préférable de créer une base temporaire, y inscrire le nouveau schéma, y copier les données manuelle avec une requête ou un bout de code afin de conserver la cohérence entre les données.
Note : Cet outil fait partie de la classe « gestion et réingénierie » citée plus haut.
Maintenant que la structure de la base de données est à jour il reste encore une demande du client, celui-ci a en effet des données sur deux instances de l’application (et donc deux instances de la base de données) qu’il voudrait fusionner
Outil génération de données
Dans mon exemple, j’ai utilisé un modèle de données fictif vous l’aurez compris, je n’ai donc pas de données à proprement dit. Je vais donc utiliser entre nos deux étapes principales l’outil de génération de données et vous le présenter (n’êtes-vous pas chanceux ?).
En effet Visual Studio possède un outil de génération de données très utile dans le cadre de tests. Cet outil est en fait un sous outil de ceux fournis dans le cadre d’un projet de base de données.
Mais qu’est-ce que les projets de base de données ? me direz-vous. Les projets de bases de données, comme tout projet Visual Studio permettent la réalisation d’un livrable, ici une base de données au sens large : sa définition (table, vues, schémas, rôles, prog stock, sécurité, stockage…), ses scripts de pré et post déploiement, les plans de génération de données, les plans de reprise de données et les comparaisons.
Il faut bien comprendre que cette approche est une manière différente de créer une base de données que celle que propose l’Entity Framework au travers d’EDMX. Cependant cette approche permet de gérer plus d’options autours de la base de données et de proposer plus d’outils spécifiquement pour la base de données. L’unique « défaut » de cette approche c’est qu’elle ne permet pas de générer une couche d’accès aux données pour l’applicatif que vous allez développer de la même manière que vous le feriez avec l’approche Design First ou Code First sous Entity Framework.
Ces deux méthodologies cohabitent tout de même bien via deux approches :
Je définis ma base de données depuis l’approche Design First ou Code First de l’Entity Framework et je me sers du projet de base de données comme « fourre-tout » de déploiement et d’instrumentalisation pour ma base.
Je définis ma base de données au sein de mon projet de base de données et j’utilise l’approche Database First de l’Entity Framework.
Pour créer un nouveau projet de base de données au sein de votre solution effectuez un clic droit sur votre solution dans l’explorateur de solution et cliquez sur « ajouter » puis « nouveau projet », dans la fenêtre qui apparait sélectionnez la section « base de données » à gauche puis « assistant SQL Server 2008 ».
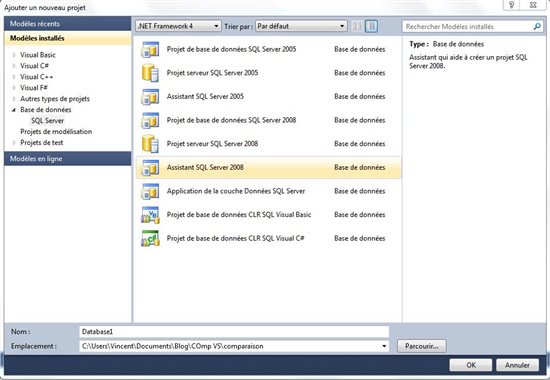
Un assistant de création du projet apparait ensuite, il s’agît d’indiquer dans notre cas que nous traiterons une base de données « classique » (contrairement aux bases qui servent à faire fonctionner SQL Server)
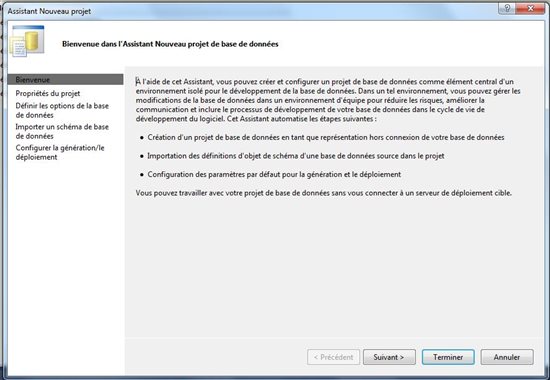
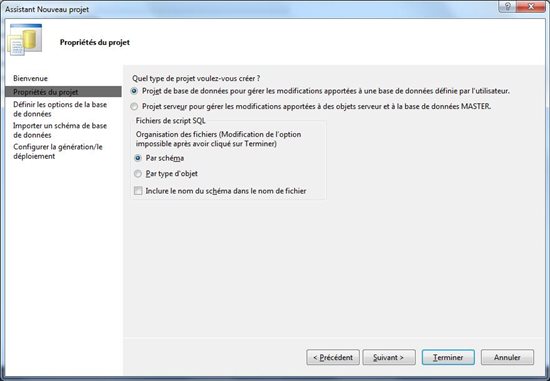
Ainsi que des options relatives à la base de données et à son déploiement
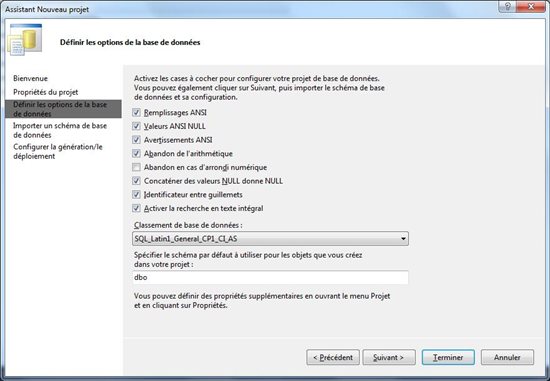
D’indiquer que nous importons une base de données existante (le dernier déploiement de mon EMX dans mon cas)
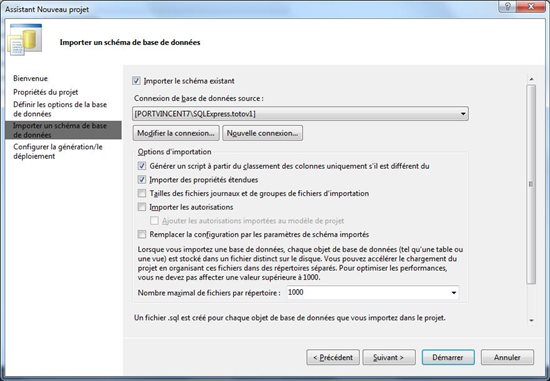
Et d’indiquer quelques derniers détails à propos du projet qui va être créé.
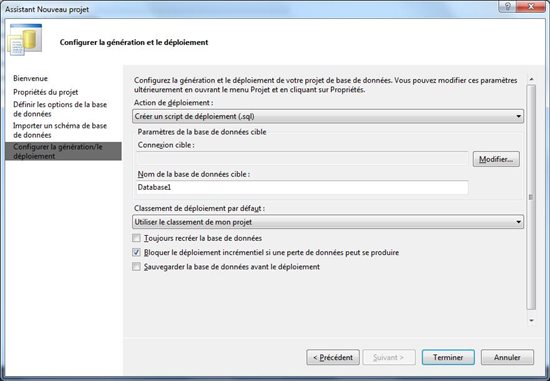
Une fois le projet créé vous le verrez apparaitre dans l’explorateur de solutions sous cette forme :
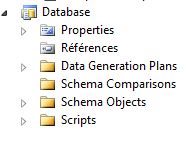
Le dossier « Data Generation Plans » contiendra les plans de génération de données (ce qui nous intéresse), « Schema Comparisons » les comparaisons de schémas (nous pourrions enregistrer la comparaison de schéma que nous venons d’effectuer précédemment à cet endroit afin de pouvoir la réutiliser plus tard sans avoir à re-paramétrer des options telles que les connexions aux bases).
Les dossiers « Schema Objects » et « Scripts » contiennent respectivement toute la définition de la base et les scripts de pré et post déploiement. Vous noterez que l’assistant a également créé des objets dans le dossier « Schema Objects » correspondants à la base que nous avons sélectionnée.
Pour créer un plan de génération des données il vous suffit de faire un clic droit sur le dossier « Data Generation Plans », « Ajouter » et « Plan de génération des données ».
Vous aurez devant vous une interface similaire à celle-ci qui vous permettra de gérer le nombre de données à générer ainsi que l’associativité de ces données.
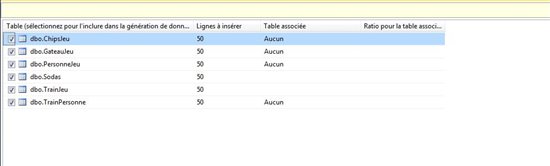
Presser simplement la touche F5 et spécifier la base de données cible pour générer des données et les insérer.
Note : cet outil (génération de données) fait partie de la catégorie « gestion et réingénierie » citée plus haut.
Maintenant que nous avons contrôlé que nos deux bases avaient des schémas identiques et que nous savons qu’elles ont des données différentes que nous devons reprendre, nous allons voir l’outil de comparaison des données.
Note : Si vous voulez aller plus loin dans les projets de base de données et dans la génération de données, n’hésitez pas à consulter ces deux ressources.
https://www.mssqltips.com/tip.asp?tip=2190
https://www.visualstudiotutor.com/2010/08/manage-database-projects-with-visual-studio-2010/
Outil de comparaison de données
Dernière partie de notre article avant la conclusion donc, la comparaison (et l’éventuelle récupération) des données de deux bases de données identiques (du point de vue de leur conception). Notez que la comparaison de données peut ne pas fonctionner sur des tables qui n’ont pas de clefs primaires.
Remarque : les tables sans clefs primaire n’ont lieu d’être que dans certains rares cas, même si on n’a pas le besoin fonctionnel d’une clef primaire il est toujours préférable d’en avoir une sur chacune des tables, ne serait-ce qu’à des fins techniques.
Pour lancer une nouvelle comparaison de données cliquez sur « données », « comparaison de données », « nouvelle comparaison de données ». Une nouvelle fenêtre apparait alors vous demandant de spécifier les connexions aux bases de données source et de destination.
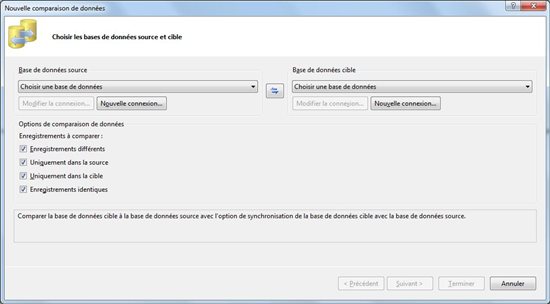
Configurez donc les connexions et cliquez sur « Suivant »
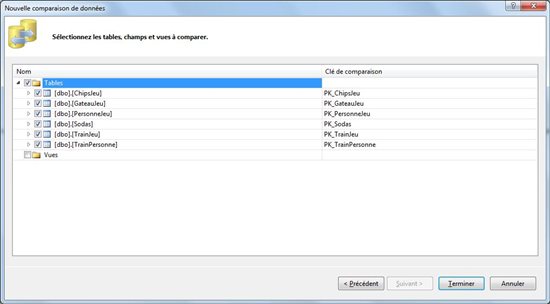
Sélectionnez les éléments à comparer (tables et vues) et cliquez sur « terminer ».
La comparaison des données démarre, cette étape peut prendre quelques secondes à plusieurs dizaines de minutes selon les performances de votre machines, des serveurs SQL, des connexions et selon la charge en cours (à ce propos, évitez d’effectuer des opérations de ce genre aux heures de pointes). Apparait ensuite un rapport sur les différences trouvées entre les jeux de données des deux bases.

Un volet en bas vous permet de voir le détail des enregistrements par table/vue avant d’écrire les mises à jour et tout comme la comparaison de schéma vous avez la possibilité d’écrire les mises à jour et/ou de les envoyer vers l’éditeur ou un fichier. Actualisez ensuite la comparaison pour vous assurer que les données sont à présent identiques.
Note : Cet outil fait partie de la classe « gestion et réingénierie » citée plus haut.
Nous venons donc de voir ce dernier outil très utile qu’est la comparaison de données, passons maintenant à la conclusion.
Conclusion
Nous avons fait un tour rapide des fonctionnalités que Visual Studio offre en matière de données. Ces fonctionnalités simples mais puissantes vous permettent d’être plus efficace dans le travail fastidieux qu’est celui de gérer la cohérence des modèles et des données.
Tip : Les outils de comparaison se coupleront très bien avec un contrôle de code source pour gérer le versionning d’une base de données et de son modèle.
Pour poursuivre votre maitrise de Visual Studio 2010 et des outils fournis je vous conseille de vous documenter sur les outils de tests (et notamment les possibilités qu’ils offrent pour ce qui est « tests des données » et « tests grâce à une source de données »)
Merci pour votre lecture et n’hésitez pas à commenter pour toute remarque, question ou suggestion.
Merci à Benjamin ARKI pour sa relecture et sa correction.